
У попередній статті я вже згадував, що зараз працюю над міграцією ETL процесів з Talend до Boomi. Тож тепер я можу порівняти ці дві системи: що зручно, що не дуже, та де які особливості.
Перед тим як я продовжу, хочу зазначити, що всі мої судження суб’єктивні та можуть відрізнятися від вашого досвіду. Я працював з процесами, які починали розробляти на Talend 10 років тому, та зараз вони можуть здаватися спадщиною «кривавого Enterprise», тож не дивуйтесь, що мій досвід скоріш негативний.
Середовище розробника
Перше, з чим стикається розробник, — це робоче середовище.
Talend пропонує Talend Studio, яка зібрана на базі Eclipse. Рішення універсальне, та не скажу, що зручне. Можливо, це в мене посттравматичне з минулого досвіду роботи з Eclipse, але мені не зайшло, бо все працювало, м’яко кажучи, нешвидко:
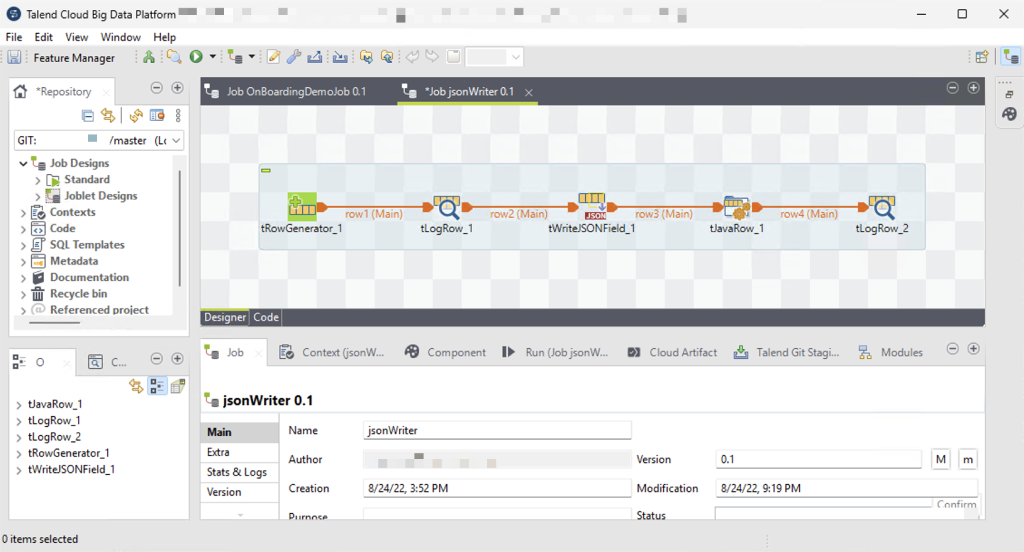
Boomi Platform — це сучасне рішення для iPaaS. Для розробки вам достатньо браузера, нічого додатково встановлювати не треба, не треба інструкцій, ліцензій тощо. Все зроблено добре, у мене майже немає нарікань на роботу їхньої платформи.
Версійність «коду»
Talend використовує Git «під капотом», і усі процеси ви зберігаєте у репозиторії. Ви маєте можливість віддати процес штучному інтелекту, він розбере його та зможе в подальшому відповідати на питання стосовно того, що та як робить цей процес. Це дуже допомагає, особливо коли відсутні вимоги, та процес міграції перетворюється на такий собі реверс-інженіринг.
Boomi теж має версійність, вона вбудована в платформу. Ви можете швидко перейти до попередньої версії процесу або навіть компонента, можете завантажити XML вашого процесу. Це, звісно, зручно, та ось доступу до репозиторію, як у Talend, ви не маєте. Додайте сюди ще відсутність блокування процесу під час редагування, і потенційно ви матимете клопіт під час одночасного редагування процесів.
⚠️ Обидві системи мають можливість створювати гілки, та моя вам порада: не користуйтесь цією можливістю без нагальної потреби та тримайтесь однієї гілки (або створіть гілку на процес). Інакше розгрібати конфлікти в цих системах — це ще той виклик. Дотримуйтесь простого правила — одночасно над процесом повинен працювати лише один розробник.
Робота з базами даних
Обидві системи в мене працювали з MSSQL, обидві системи для цього використовували один і той самий Microsoft JDBC Driver. Для Talend ця можливість їде «з коробки», для Boomi слід було завантажувати драйвер як JAR файл на Runtime.
Та далі я розкажу про особливості, з якими стикнувся вже у Boomi, бо у Talend я бачив реалізацію, та не знаю, які були виклики перед розробниками і чому вони реалізовували те або інше рішення.
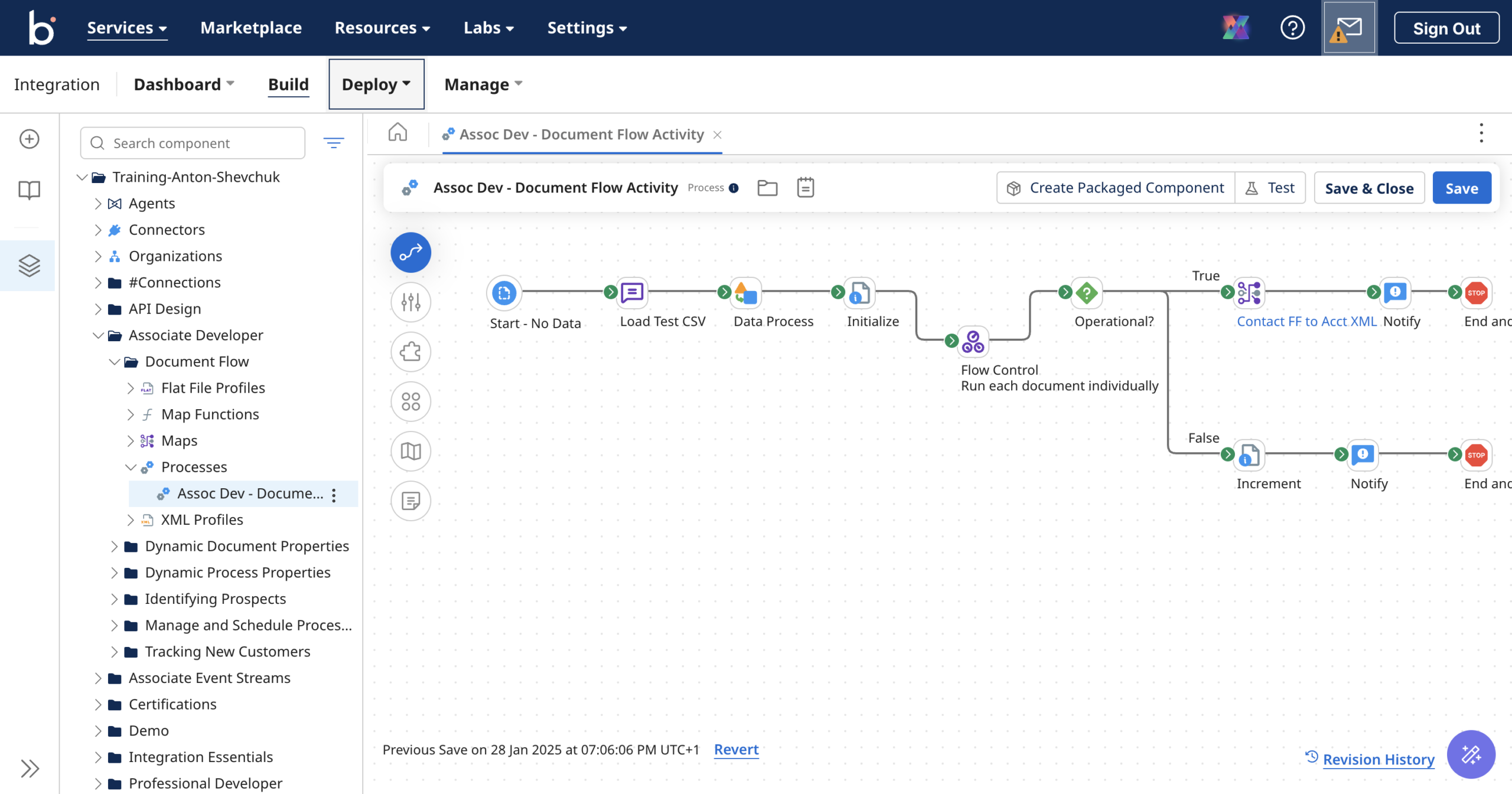
Boomi на даний момент має два конектори до баз даних.
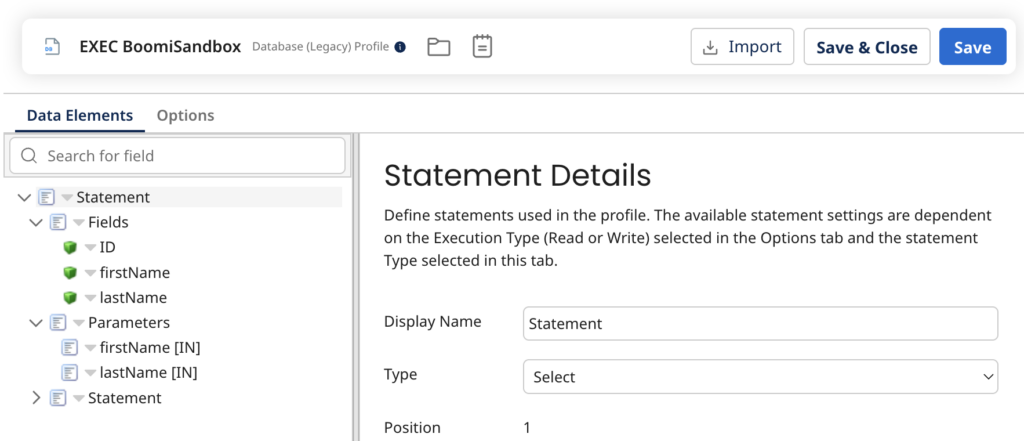
Перший — це «Database (Legacy)». Він досить гнучкий та універсальний, та він має одну ваду: він оперує документами, які використовують профіль особливого формату. Вони фактично описують не документ, а саме запит до бази даних. Це незручно, коли ви будуєте процес: вам треба створювати потім окремий профіль для документів та мапінг для перетворення з одного в інший.
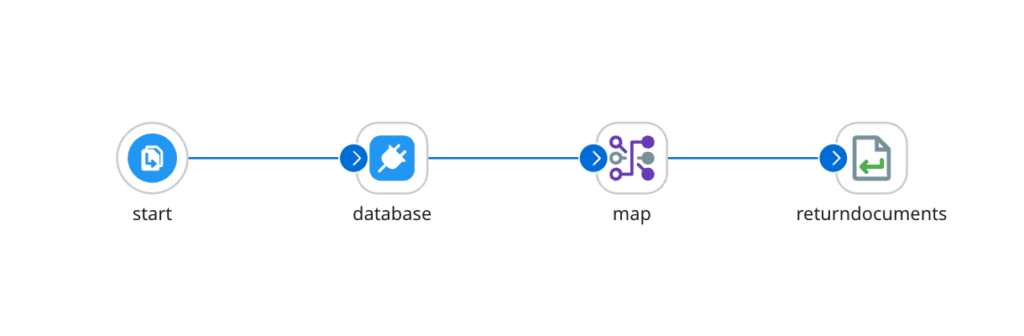
Цю проблему вирішує конектор «Database V2». Він вже працює з універсальним профілем документів у форматі JSON, та і запит до БД перенесли до «операцій», що виглядає більш логічно:
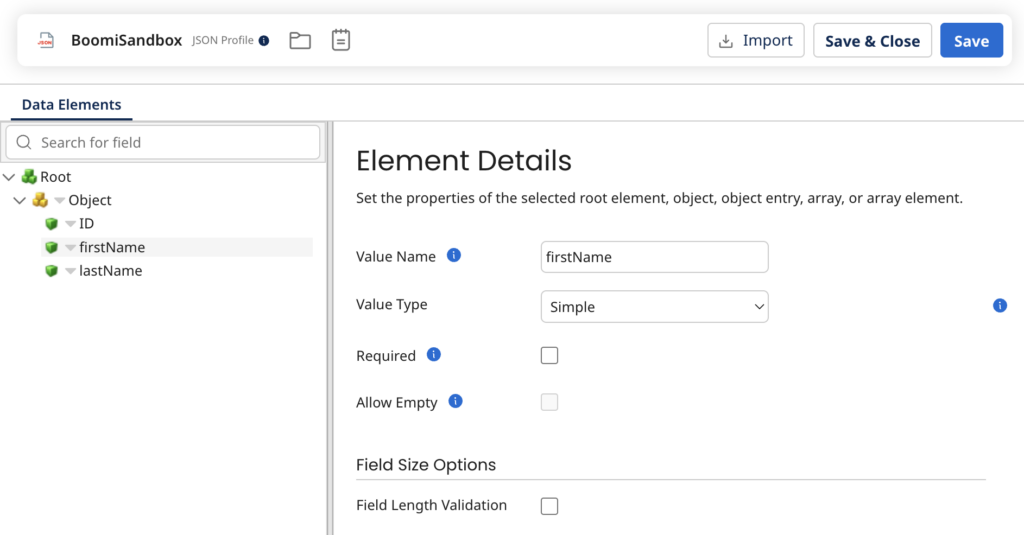
Але цей конектор, на мій погляд, вже не такий гнучкий, як попередня версія, та можу навіть сказати, що він трохи «сирий», бо має дитячі вади з валідацією синтаксису запитів.
Також у Boomi є обмеження щодо роботи з temporary tables. Оскільки такі таблиці існують в межах одного з’єднання (connection), то працювати з ними можна лише в межах одного шейпу процесу. Boomi не гарантує, що два окремих шейпи з викликом до БД будуть відбуватися в межах одного і того ж з’єднання, а не іншого з пулу конектів.
Та що для мене було важливо — це те, що зрозумілим та знайомим виявився механізм роботи з транзакціями та блоком try-catch, і це майже в кожному процесі доводилось робити:
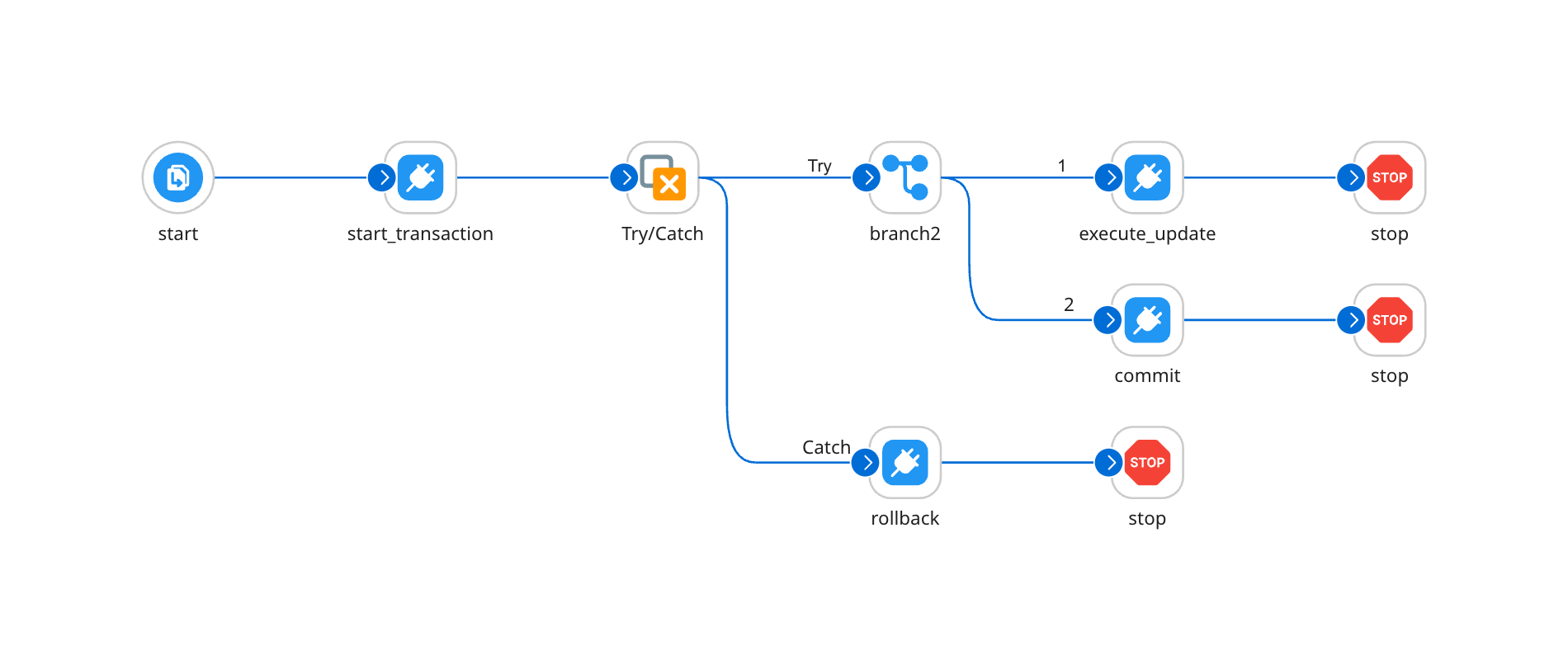
Виглядає це дуже примітивно, та тим не менш працює ефективно та зрозуміло будь-якому розробнику.
Mapping
Talend має можливість мульти-мапінгу — це коли фактично ми зливаємо декілька документів в один або перетворюємо в декілька.
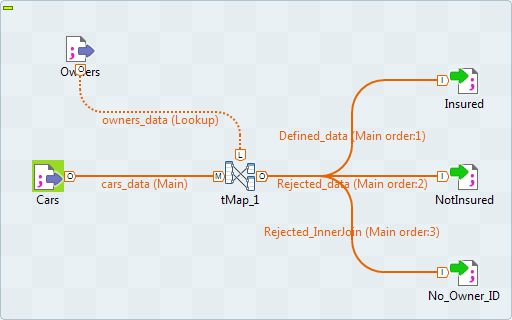
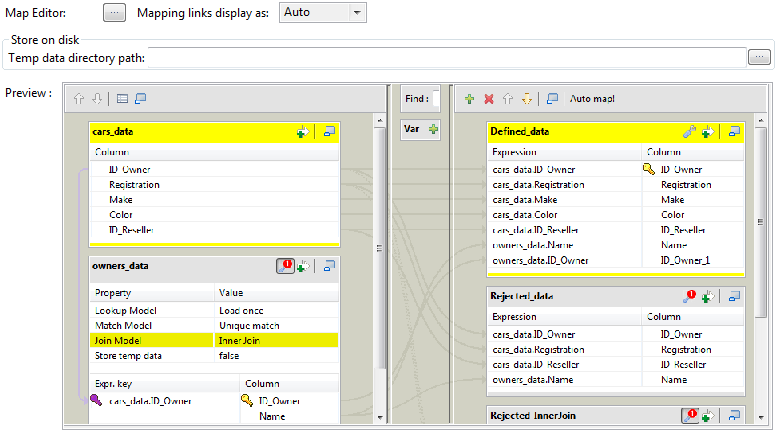
Скріни взяті з офіційного мануалу компанії QlikTech International AB.
В Boomi важче злити два документи до одного. Для цього треба додавати мапінг-функцію на всі поля, або робити кастомний скрипт, який буде це робити, та ще, можливо, слід буде городити додатковий кеш до цього всього:
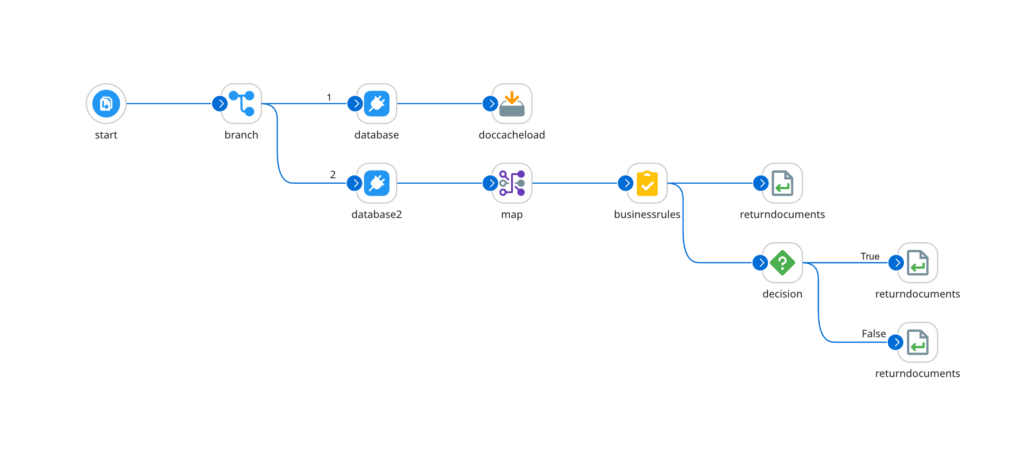
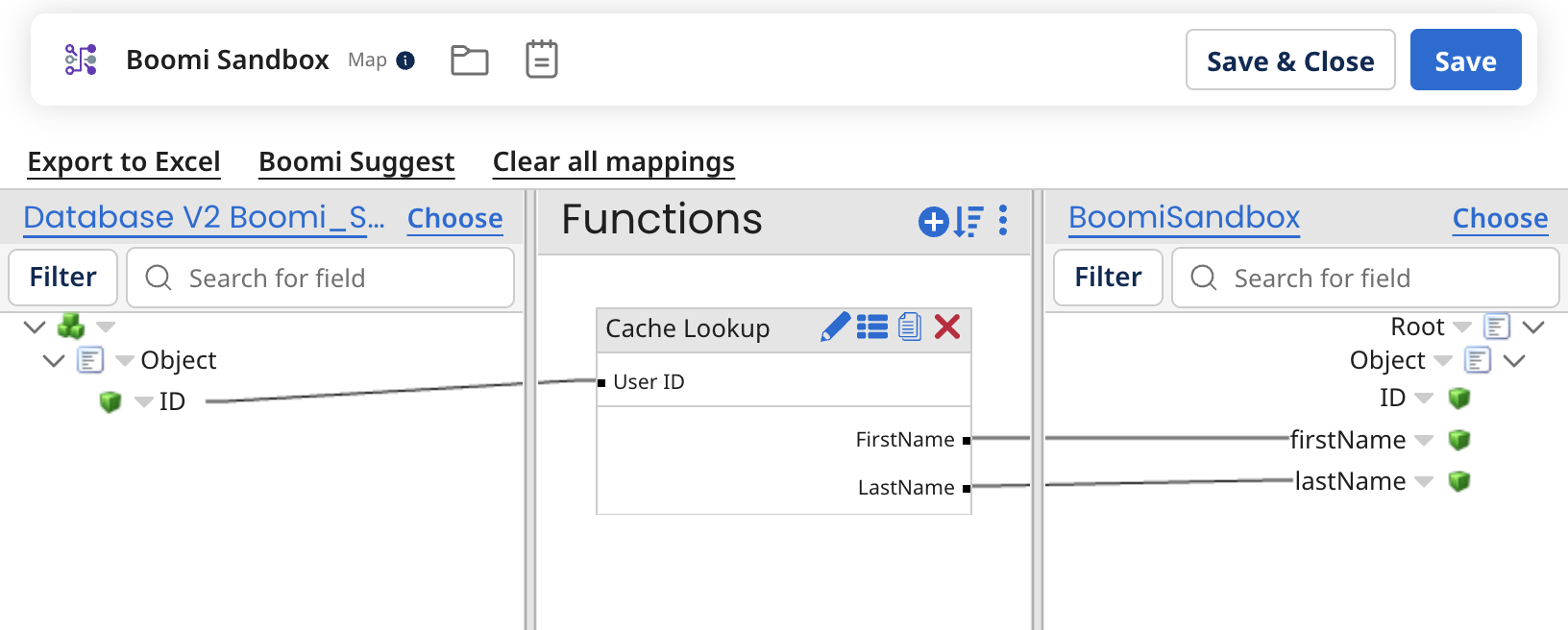
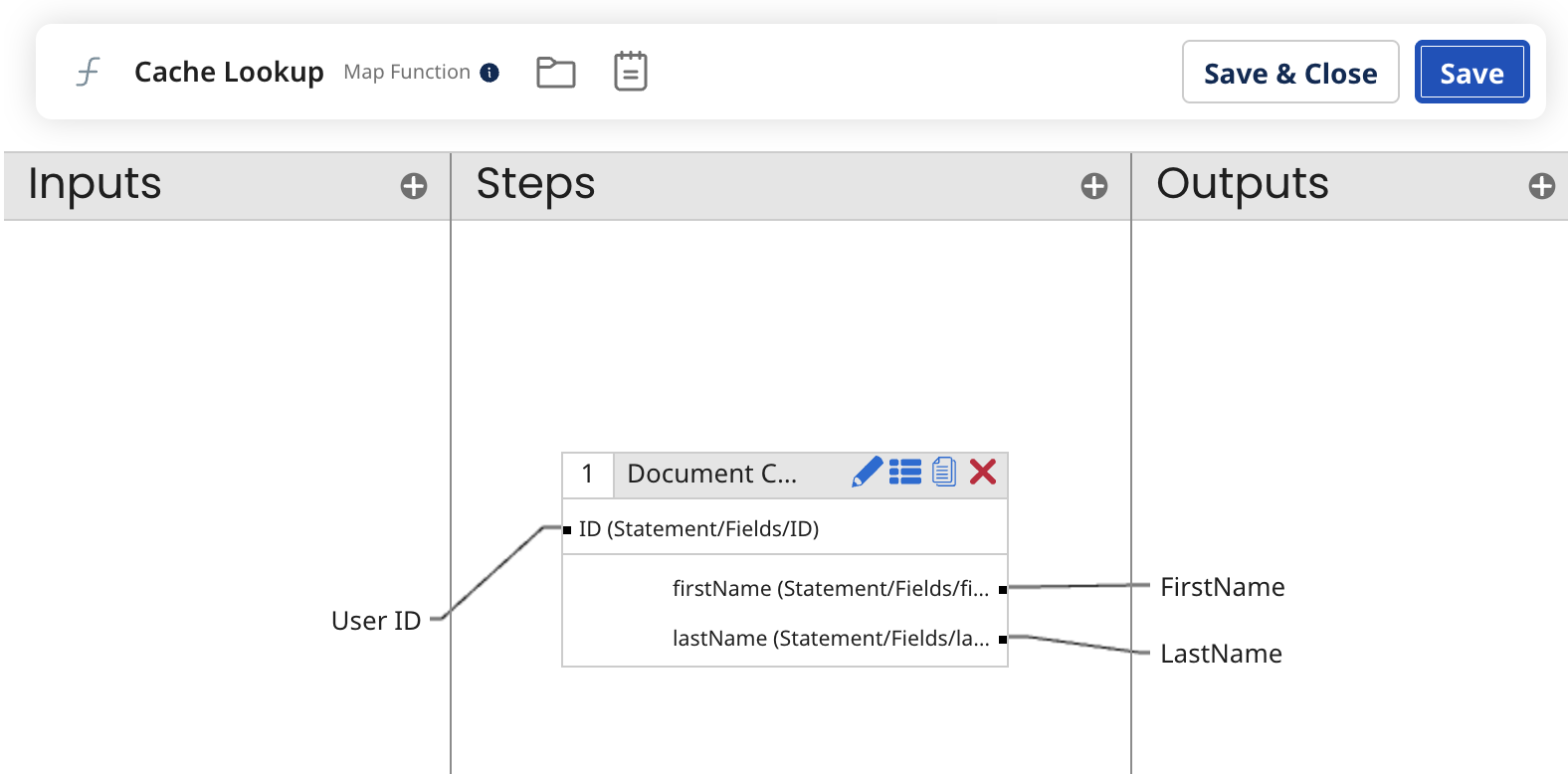
Наче Boomi-варіант менш гнучкий, та реалізація в Talend має великий недолік: подібний мапінг погіршує читабельність (readability) процесу. Додайте до цього відсутність пошуку полів, і перевага Talend дуже швидко перетворюється на суцільний головний біль.
На мою думку, мапінг в Boomi більш зрозумілий, використання функцій для мапінгу дисциплінує та дозволяє зручно перевикористовувати код (я про це ще розповім).
Мій досвід з мапінгом в Talend я б назвав травматичним, бо кожного разу він виглядав для мене як зустріч з Демогоргоном:

Динамічна конфігурація
Те, чого концептуально неможливо зробити в Boomi, — це конфігурувати з’єднання під час виконання процесу. Не можна змінити connection string до бази даних під час виконання процесу; не можна підставити іншу конфігурацію SFTP після запуску. Ці та інші налаштування ви повинні встановлювати для процесу перед початком виконання.
З одного боку, це звісно «хард» обмеження, та це зроблено навмисно, бо фактично це є фундамент для ваших розрахунків з Boomi (ліцензування конекторів). Але з іншого боку, гарно спроєктований процес буде знати заздалегідь всі можливі конекти ще на початку своєї роботи.
Зрештою, процеси, які потребували подібного підходу, були реалізовані, та це потребувало додаткового часу на конфігурацію.
Перевикористання «коду»
І Talend, і Boomi дають можливість створювати саб-процеси та використовувати їх у основному процесі.
Можу зазначити, що виклик саб-процесів у Talend зроблено зручніше, бо налаштування запуску конфігуруються безпосередньо у властивостях елемента, який викликає саб-процес. В Boomi для цього доводиться використовувати окремий додатковий елемент «Set Properties»:
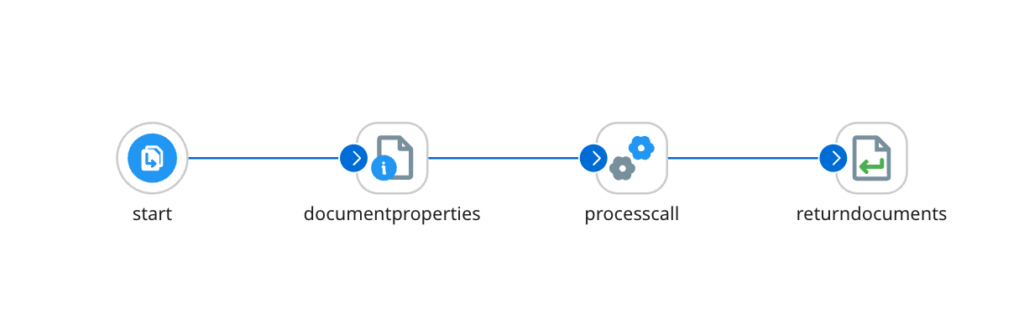
Наче й не складно, та все ж таки варіант, який пропонує Talend, мені здається більш логічним. А варіант від Boomi у випадку виклику саб-процесу декілька разів потребує додаткової уваги, щоб не наробити помилок.
Кастомний код
Talend дозволяє вставити Java код майже в кожне поле. Це виглядає гнучко як концепція, але моя робота дуже часто виглядала як оцей мем з розслідуванням:

Також в Talend є можливість створювати та додавати кастомні Java бібліотеки, щоб потім використовувати їх. Угу, викликати Java-бібліотеку можна майже з будь-якого поля, тут вже інший мем…

При роботі з Boomi ви теж можете використовувати кастомні Java-бібліотеки, такі як iText чи jsoup, або написати свою власну. Але розробляти та компілювати ви будете поза Boomi, а на платформу завантажуватимете вже готові JAR-файли.
Використання кастомного коду в Boomi обмежено Process Script та Map Script, їх завжди легко знайти серед компонентів:
Для використання кастомних бібліотек ви все одно будете використовувати JavaScript або Groovy. Як я зазначав у попередній статті, в мене виникають питання лише з приводу версій, які підтримує Boomi: код слід писати як 10 років тому, наче й не проблема, та все одно трохи дратує.
Переваги Boomi
Є у Boomi один великий плюс — це можливість перевикористовувати майже усі компоненти: екшени, профілі, мапінги та скрипти без того, щоб оформляти їх як Java-бібліотеки. Це прям сильно спрощує життя розробникам. Головне — оці загальні компоненти оформлювати, документувати та шерити знання про них серед команди.
Як я вже зазначив вище, реалізація транзакцій та робота з try-catch реалізована зручно та передбачувано.
Були й інші моменти, коли я радів функціоналу Boomi, якого не було в Talend (чи, можливо, розробники просто не використовували той функціонал, бо він з’явився пізніше за створення процесу).
Як приклад — PGP Encrypt/Decrypt. В Boomi ви завантажуєте сертифікат через інтерфейс та використовуєте його в Data Process шейпі:
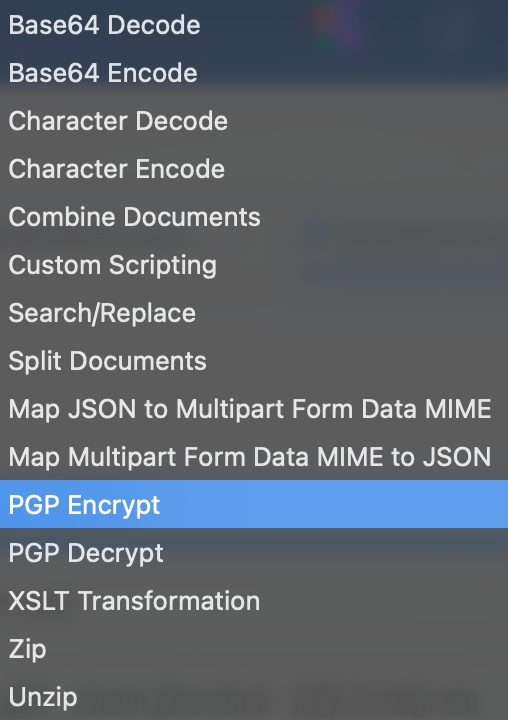
Як бачите, є робота з Base64 через UI, а не з коду; те саме з Zip архівацією.
Дуже просунуте логування, яке дозволяє легко дебажити процеси, аналізувати перформанс та знаходити проблемні місця:
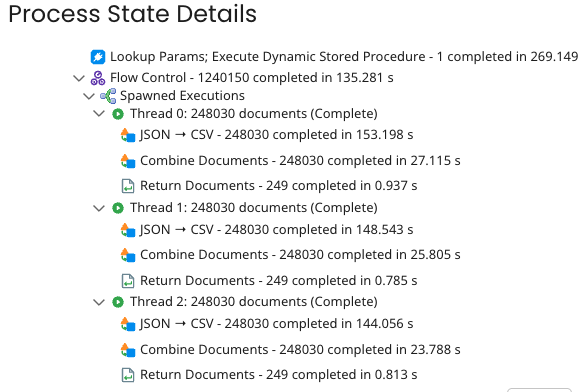
Додам, що Boomi має ще одну велику перевагу — він має вбудований функціонал з AI, який вміє документувати процеси (і це не єдине, що він вміє). Робить він це, не сказати, що прям добре — я б оцінив на 3 з 5 зірочок. Мені особисто не вистачає можливості, щоб AI розумів саб-процеси та переходив по ним.

Можу відзначити також значний прогрес їхнього AI для побудови процесів: він стає розумнішим, та, на мою думку, йому ще зарано будувати процеси самостійно. Можливо, за пів року або рік це стане дійсно корисним інструментом.
Недоліки Boomi
Головний недолік, на який я вже скаржився в попередній статті, — це те, що логування, яке я нахвалював раніше, дуже сильно впливає на швидкодію. Вимкнути його для процесів, які виконуються за розкладом, неможливо, і як результат — різниця в часі виконання між Talend та Boomi одного і того ж процесу у 3-4 рази.
Окремо існує проблема: коли у вас велика кількість документів (мільйони), то не варто намагатися їх порахувати в Boomi, це сильно впливає на швидкодію. Ось так не робіть:
Що можна покращити в Boomi?
Це нотатка скоріш для розробників Boomi, і сподіваюсь вона дістанеться свого адресата.
Робота з Dynamic Process Properties (DPP) та Dynamic Document Properties (DDP) вимагає постійно «пам’ятати» назви цих Properties. Використовуєш їх постійно, доводиться копіювати назви, а це незручно і викликає помилки. Було б добре, щоб система відслідковувала DPP та DDP під час розробки та давала можливість обирати з попередньо створених. Також під час виконання процесу у Test Mode хотілось би мати можливість бачити, що у тих Properties відбувається, щоб не робити це за допомогою окремих елементів.
Роботу з профілями документів теж можна покращити — коли перший елемент процесу повертає якийсь профіль, та ми додаємо наступний елемент, такий як Map, то було б зручно, якби він автоматично розумів контекст та брав відповідний профіль. Наразі система не підказує, який профіль обрати, що призводить до помилок, які доволі часто трапляються під час розробки, хоча і діагностуються теж легко.
Що треба знати? Або чому Low-Code не означає No-Knowledge
Якщо ви думаєте, що робота з Boomi — це лише перетягування іконок, мушу вас розчарувати. Щоб будувати серйозні рішення, вам знадобиться комплексний технічний бекграунд, і ось чому.
Почнемо з програмування. Так, Boomi дозволяє багато зробити візуально, але як тільки логіка стає нестандартною, вам доведеться писати скрипти. Тут панує JavaScript, але є нюанс: це старий добрий ECMAScript 5, тому забудьте про модні фішки сучасного JS. А оскільки платформа працює на Java-машині, то знання Java або Groovy стає вашим секретним козирем для вирішення задач, які не під силу звичайному JS. Ну і, звісно, розуміння структур даних та вміння писати тести ніхто не скасовував.
Далі — робота з даними, адже інтеграція — це, по суті, перекладання даних з однієї кишені в іншу. Ви маєте вільно почуватися з базами даних, і мова не про прості SELECT-запити. Реальні кейси вимагають роботи зі збереженими процедурами (Stored Procedures) та транзакціями, особливо в MSSQL. Крім того, вашими постійними супутниками стануть JSON та XML. І якщо JSON — це стандарт сучасного світу, то XML та вміння писати для нього XSLT-трансформації — це сувора реальність Enterprise-систем, яку треба прийняти.
Щодо зв’язку систем, то тут ви маєте бути поліглотом. REST API — це ваша база: ви повинні розуміти, як працюють HTTP-методи та авторизація. Але Enterprise не був би Enterprise’ом без SOAP-сервісів, тож доведеться навчитися «дружити» і з ними. А для побудови сучасних асинхронних архітектур вам знадобиться досвід роботи з чергами повідомлень, зокрема з Apache Kafka, щоб ваші системи могли обмінюватися даними миттєво і надійно.
І наостанок — інфраструктура та безпека. Ваш процес не висить у вакуумі. Ви повинні розуміти хмарне середовище: що таке балансувальники навантаження, як працює автоскейлінг та як моніторити здоров’я системи. І, звісно, безпека: розібратися в OAuth, SSL сертифікатах та інших методах автентифікації — це не опція, а необхідність, щоб ваші інтеграції не стали діркою в безпеці компанії.
Boomi. Такий шлях
Ця стаття не претендує на хайповий заголовок Boomi VS Talend, бо в першу чергу я хотів поділитися своїм досвідом та мав за ціль підкреслити один факт: міграція з Talend до Boomi можлива. Та чи потрібна вона вам і вашій компанії? Ось тут я не зможу відповісти, я лише намагався трошки надати вам аргументів, якщо перед вами постане таке питання. Для однозначної відповіді вам треба зважити дуже багато факторів, серед яких буде і ціна рішення, і ціна міграції, і ціна навчання нової системи.
З останнім я вам підкажу трохи. На мою думку, щоб навчитися працювати з Boomi, слід орієнтуватися на 1 місяць інтенсивного навчання. Перші два тижні потрібні, щоб пройти Integration Developer Path та декілька супутніх топіків. Після цього можна буде починати брати перші прості інтеграційні процеси до роботи. Наступні 2 тижні — це буде занурення до прикладів реалізації, до мануалів, напрацювання best practice, та в залежності від ваших вимог та потреб можливо слід буде пройти курс Associate Event Streams та Professional API Design. Загалом, за місяць перекваліфікуватися до System Integration Engineer можливо, але за умови, що вже є базові знання.
P.S.
Якщо ви теж проходили цей шлях міграції або маєте свої «милиці» та лайфхаки для Boomi — діліться в коментарях, цікаво почути про ваш досвід. І окремо буду щиро вдячний, якщо хтось підкаже елегантний спосіб обійти проблему з гальмуванням логів. Бо поки що це виглядає як вибір без вибору, і мене це гризе.
P.P.S.
Під час міграції жоден Talend-розробник не постраждав…