
Ох, давненько я ничего в блог не писал… Да вот давеча захотел я добавить Instant View представление для своих постов, посидел пару часиков над ним, а потом не удержался и оформил руководство по данной теме. Так что далее я расскажу о том что это, и как создать Instant View для своего блога.
Что такое Instant View?
Это технология быстрого просмотра ссылок непосредственно в интерфейсе Telegram, можете попробовать перейти по ссылке и зашарить её в Телеграме:
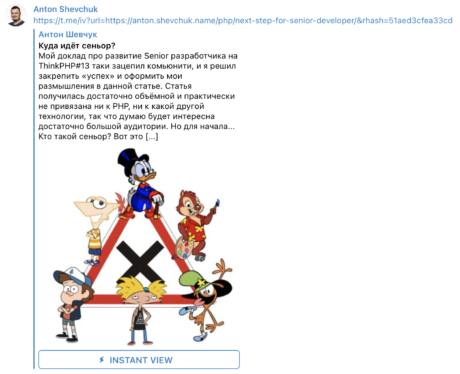
Далее кликаем по ⚡︎ INSTANT VIEW и получаем вот такое представление:
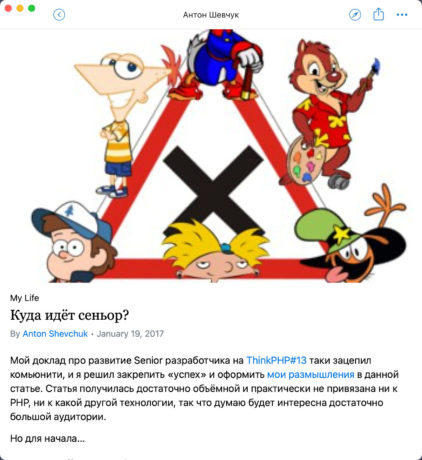
Как работает Instant View?
Специальный бот от Телеграм увидя ссылку в тексте сообщения проверяет, есть ли для неё шаблон, и если есть, то использует его для преобразования контента и показа пользователю. Таким образом, коль вам нужен Instant View для блога, то всё сводится к созданию шаблона для преобразования.
— Ясно-понятно…
Как создать свой шаблон?
Шаг 1. Dashboard
Переходим на домашнюю страницу Instant View и заходим в свой профиль телеграма (в правой колонке в самом низу будет Login). Затем переходим на страницу шаблонов My Templates и в единственное поле на странице вбиваем ссылку на подопытную статью:
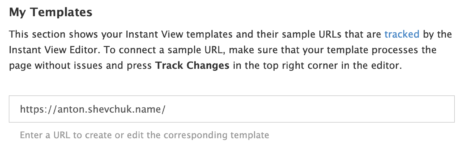
Я тут вбил ссылку на главную страницу, да только именно для главной страницы Instant View не особо нужен. В качестве подопытного лучше выбрать непосредственно пост блога, можно начать с чего-то простого, чтобы не увязнуть в разборе ошибок.
Шаг 2. Редактор шаблонов
После этого мы попадём в редактор шаблонов. В редакторе перед нами будет 3 окошка — собственно страница нашего сайта, редактор шаблона, и предпросмотр Instant View:

На картинке уже есть текст шаблона, а вас встретит пустой редактор.
Шаг 3. Редактирование
А теперь нас ждут первые напряги, и связаны они будут с тем, что нам надо будет изучать мануал, и не только по Instant View, но и по XPath. Но обо всём по порядку.
Начнём с версии шаблона, тут пока всё просто, будем использовать самую свежую из доступных:
~version: "2.1"
Первая строчка шаблона есть! Ну, а теперь нам необходимо указать боту IV где искать заголовок и непосредственно контент статьи. Ага, только нам бы самим найти для начала:
- открываем подопытную страницу в отдельной вкладке вашего браузера;
- кликаем правой кнопкой мыши на заголовке и выбираем пункт
Inspect element; - перед вами откроется консоль вашего браузера, и среди прочего кода страницы будет подсвечен целевой элемент;
- правой кнопкой мыши по нему, и выбираем пункты
Copy>Copy XPath; - вставляем в редактор шаблона получившийся результат;
- повторяем данные пункты для контента статьи.
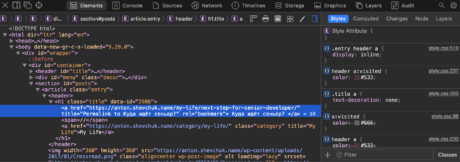
Вот мои результаты для заголовка title и для контента body:
~version: "2.1" title: //*[@id="posts"]/article/header/h1/a[1] body: //*[@id="posts"]/article
Если всё хорошо, то у нас уже должен появится результат в правом окошке редактора:
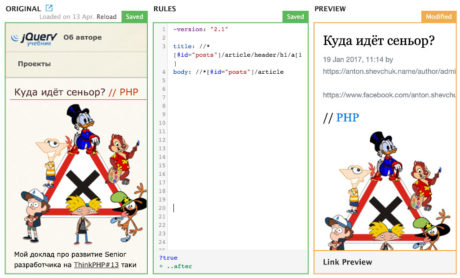
Или не появится, и вам насыпет кучу ошибок, но это всё поправимо. Про свои ошибки и обходные пути я тоже буду рассказывать дальше
Далеко от идеала, нам бы подправить ещё обложку:
# нам нужна первая картинка в посте cover: //*[@id="posts"]/article/img
Дату публикации тоже стоит выделить:
published_date: //*[@id="posts"]/article/footer/time
Информацию о авторе я использую статическую, т.к. я единственный автор своего блога:
author: "Anton Shevchuk" author_url: "https://anton.shevchuk.name"
Так, ещё есть ряд свойств, которые относятся к оформлению ссылок, меня же интересует пока только image_url — картинка для ссылки. В качестве оной я опять буду брать первую картинку из текста статьи:
image_url: //*[@id="posts"]/article/img
Дальше опять чуток напрягов, я хочу использовать данный шаблон только для страниц и постов, а они у меня отличаются от прочих страниц лишь тем, что для заголовка используется тег H1, чтобы добавить такую проверку следует использовать условие exists:
?exists: //*[@id="posts"]/article/header/h1
На странице ещё остались “остатки” от заголовка и метаданных в футере, их следует удалить (данные правила я добавил в самый конец шаблона, т.к. порядок имеет значение):
# not necessary @remove: //*[@id="posts"]/article/header @remove: //*[@id="posts"]/article/footer
Чуть-чуть оптимизации — добавлю переменную, в которой собственно и буду хранить XPath к статье:
# variables
$article: //section[@id="posts"]/article[has-class("entry")]
Я слегка изменил исходный XPath, чтобы он был более однозначным — добавил название тега с
id="posts", да иarticleу меня всегда указан с классомentry
Итоговый шаблон обрёл завершённый вид:
~version: "2.1"
# variables
$article: //section[@id="posts"]/article[has-class("entry")]
# only for posts and pages
?exists: $article/header/h1
# main
title: $article/header/h1/a[1]
kicker: $article/header/h1/a[2]
cover: $article/header/following::img
published_date: $article/footer/time
body: $article
# author
author: "Anton Shevchuk"
author_url: "https://anton.shevchuk.name"
# preview
image_url: $article/header/following::img
# not necessary
@remove: $article/header
@remove: $article/footer
Кликнув по ссылке VIEW IN TELEGRAM вы можете посмотреть на результат моих трудов.
Шаг 4. Отслеживание страниц
Когда шаблон для подопытной страницы готов нажимайте на ссылку TRACK CHANGES в правом верхнем углу — теперь бот будет отслеживать данную страницу на ошибки и изменения которые будут появляться после изменения шаблона.
Выбирайте следующую страницу сайта и проверяйте шаблон на ней. Если вы вносили изменения в шаблон, то бот проверить все отслеживаемые страницы и отобразит статус:
![]()
Для тех страниц, что помечены как модифицированные вы должны подтвердить правки, для страниц с ошибками следует всё исправить.
Как только у вас наберётся с десяток страниц, то можно будет опубликовать шаблон используя кнопку Submit template. После прохождения проверки администрацией ваш шаблон будет доступен для автоматической генерации Instant View, а до тех пор придется довольствоваться ссылками для предпросмотра. Такие ссылки выглядят не очень презентабельно, но уже что-то:
# format
https://t.me/iv?url={%URL%}&rhash={%RHASH%}
# example
https://t.me/iv?url=https://anton.shevchuk.name/php/next-step-for-senior-developer/&rhash=51aed3cfea33cd
Список возможных свойств которые можно использовать в шаблоне доступен на странице документации, но для для удобства я его скопировал и упорядочил:
| Параметр | Тип | Описание |
|---|---|---|
| title обязательный | RichText | Заголовок страницы |
| subtitle | RichText | Подзаголовок страниц |
| cover | Media (Image/Video/Embed/Map) | Обложка статьи |
| body обязательный | Article | Содержание страницы |
| kicker | RichText | Кикер |
| published_date | Unixtime | Дата публикации |
| Параметр | Тип | Описание |
|---|---|---|
| author | String | Имя автора |
| author_url | Url | Ссылка на автора |
| channel | String | Профиль или канал автора в формате @username |
| Параметр | Тип | Описание |
|---|---|---|
| site_name | String | Имя сайта |
| description | String | Короткое описание |
| image_url | Url | Изображение |
| document_url | Url | Ссылка на документ |
Отладка
Для отладки у нас есть аж одна функция — debug. С её помощью можно проверить, что именно было найдено с помощью XPath:
# вот мы передаём XPath в явном виде @debug: //article/img # а тут мы используем специальный символ $$ # так мы берём XPath который использовала предыдущая функция @debug: $$ # это сокращенная форма того, что выше, XPath всё ещё тот же @debug
После сохранения шаблона внизу страницы появится отладочная информация:

Ещё один способ использовать debug – просмотреть результат выполнения предыдущей функции, т.е. показать не то с чем работала предыдущая функция, а именно то, что у неё получилось:
# это вызов функции, мы про них ещё поговорим @before(@title): $article//a//img # а вот так выводим результат её работы @debug: $@

Типичные ошибки
Мне кажется, этот раздел стоило бы назвать “Мои ошибки” :)
Element <img> is not supported in <p>
Шаблонизатору IV не нравится, когда картинки засовывают в другие элементы, поэтому их желательно “извлечь” — для этого воспользуемся функцией split_parent:
# <p> # Текст до фотографии # <img src="photo.jpg"> # Текст после фотографии # </p> @split_parent: //p/img # <p> # Текст до фотографии # </p> # <img src="photo.jpg"> # <p> # Текст после фотографии # </p>
Если в результате у вас появятся пустые параграфы, то это подчистят без вашего участия.
Альтернативный вариант — заменить <p> на <div>:
# <p> # <img src="photo.jpg"> # </p> <div>: //p/img/parent::p # <div> # <img src="photo.jpg"> # </div>
Element <img> is not supported in <a>
Следующий случай оказался сложнее — есть ссылки, внутри которых лежит картинки. У меня оказалось два варианта, и два возможных сценария изменения:
- ссылка на большую картинку — ссылку грохаем, оставляем картинку
- ссылка на что-то другое — картинку грохаем,
titleкартинки используем в качестве текста ссылки
# anchor linked to image ~> image @split_parent: $article//a[ends-with(@href, '.jpg')]//img @split_parent: $article//a[ends-with(@href, '.png')]//img # anchor with image as text ~> link @before(@title): $article//a//img @remove: $article//a//img
Embed not supported yet: <iframe …>
Instant View поддерживает ряд интеграций среди которых Twitter, YouTube, Vimeo и прочие, но список не слишком велик, и в том случае, когда шаблонизатор сталкивается с незнакомым iframe он ругается подобной ошибкой. К сожалению, всё что не знакомо мне пришлось удалить:
# unsupported @remove: $article//iframe[starts-with(@src, 'https://www.scribd.com')] @remove: $article//iframe[starts-with(@src, 'https://docs.google.com')]
А для моего WordPress?
А теперь я приведу шаблон, который я использую для своего фото-блога.
У меня фото-блог крутится на WordPress с темой Twenty FifteenVersion, и его шаблон выглядит куда как проще чем для этого блога.
И да, данный шаблон подойдёт для всех тем из семейства Twenty.
~version: "2.1"
# WordPress Theme
# Twenty Family Themes
# link preview
site_name: //header[@id="masthead"]//*[has-class("site-title")]
# regular wordpress post
?exists: //body[has-class("single-post")]
# or single page
?exists: //body[has-class("page")]
# variables
$article: //article[has-class("hentry")]
# structure
title: $article/header/h1
kicker: $article/footer//a[contains(@rel,'category')]
body: $article/div[has-class("entry-content")]
cover: $article/div[has-class("post-thumbnail")]/img
published_date: $article/footer//time[has-class("entry-date")]
# link preview for post and pages
image_url: $article/div[has-class("post-thumbnail")]/img/@src
# personal information
author: $article/footer//span[has-class("author")]/a
author_url: $article/footer//span[has-class("author")]/a/@href
Если вы единственный автор блога, то в качестве
author_urlукажите ссылку на сам блог, или на любую другую страницу о вас. Параметрchannelтоже стоит добавить, если конечно вы ведёте свой канал.
Можете посмотреть как он работает, для этого вам достаточно перейти по ссылке и зашарить её в Телеграм (я обычно пользуюсь Saved Messages для этого). Ну и да, rhash для этого шаблона 7b32af06bd787a, можете попробовать, подходит ли он вам.
Для каких страниц создавать?
Создавать Instant View представление стоит только для страниц со статичным контентом. Вот хорошие примеры:
- ✔️ пост на блоге
- ✔️ новость на портале
- ✔️ wiki-страница
- ✔️ руководство
- ✔️ документация
- ✔️ страница с описанием товара
А вот для чего не стоит использовать:
- ❌ каталог или архив статей
- ❌ страница и результаты поиска
- ❌ форумы и комментарии
- ❌ любые динамические генерируемые страницы (например как у меня главная страница блога)
- ❌ любые страницы для взаимодействия с пользователем (различные формы)
- ❌ страницы, которые требуют авторизации или платного доступа
- ❌ страницы, контент которых не поддерживается (например карты)
P.S. Для иллюстрации использована картинка с FreeVector.com
Антон, а сколько обычно у администрации занимает ревью шаблона?
Мне кажется они их больше не принимают на рассмотрение, по крайней мере для моего блога Instant View так и не заработал
:(
Тоже столкнулся с проблемой, что у меня все оформлено и горит зелёным, но шаблон так и не прошел модерацию…
Я пошел от обратного пути. Взял страницу с разметкой и разобрал ее на кирпичики, зател собрал так как мне нужно не используя шаблон в instantview.telegram.org ))
После зашел туда, отправил свою ссылку и все работает)
Натянул не разметку на шаблон, а на оборот) шаблон на разметку)
За основу взял страницу из teletype